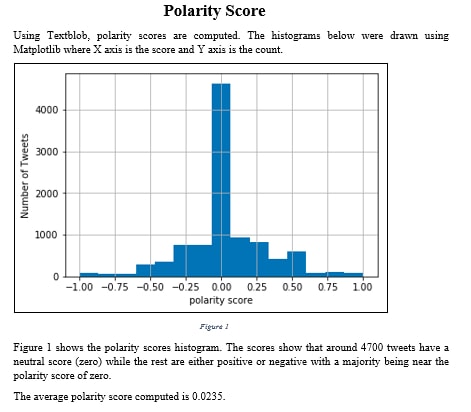
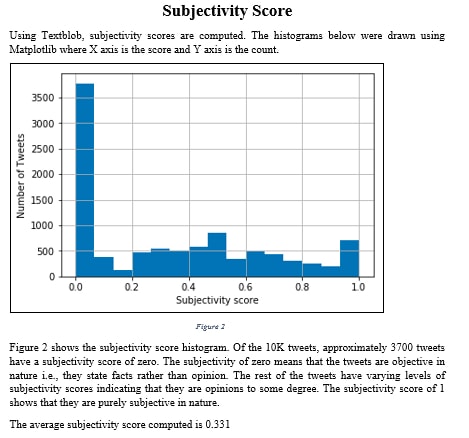
Sentiment Analysis
TextBlob is a Python (2 and 3) library for processing textual data. It provides a simple API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more. Matplotlib is a Python 2D plotting library which produces publication quality figures in a variety of hardcopy formats and interactive environments across platforms. It tries to make easy things easy and hard things possible. One can generate plots, histograms, power spectra, bar charts, error charts, scatterplots, etc., with just a few lines of code. In the figures below, TextBlob in combination with Matplotlib is used to plot the polarity and subjectivity scores based on the corpus of tweets -